How to extend LLM functionality ?
Large language models (LLMs) like GPT-3 have demonstrated impressive text generation abilities, but still have limitations in their knowledge and reasoning capacities straight out of the box. However, there are several promising techniques that can enhance LLMs' core functionalities - without the need to necessarily scale up the model sizes to massive parameters. In this post, we dive into three of the popular approaches: prompt engineering, fine-tuning, and retrieval-augmented generation (RAG). Each methodology has its own strengths and weaknesses.
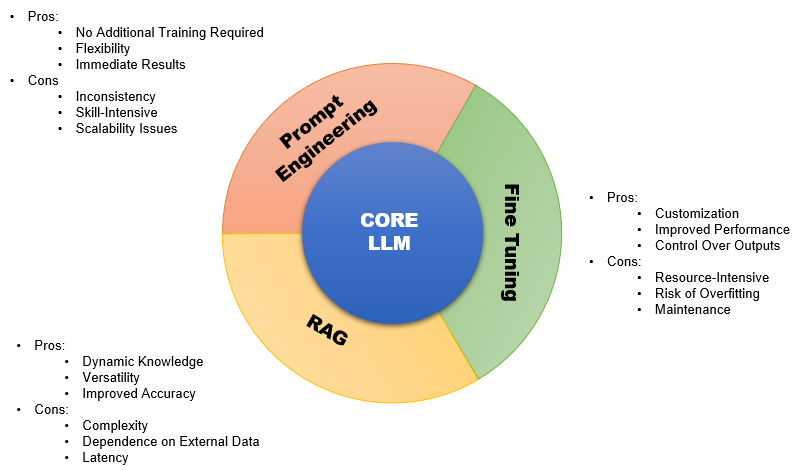
Prompt engineering leverages the model's pre-trained knowledge by carefully constructing the prompts provided to the LLM. Fine-tuning entails additional training on domain-specific datasets to customize the model's capabilities. Finally, RAG incorporates external knowledge sources on-the-fly during text generation. We discuss the pros and cons of each method and where they are best suited. Each of these technologies has its own pros and cons that can be captured as below :
- Pros:
No Additional Training Required : It doesn't require retraining the model, making it quick and cost-effective. It Allows tweaking an LLM's behavior without additional trainingFlexibility : Users can guide the model's responses by crafting prompts creatively. It would helps expose capabilities already present but not exposed by default promptsImmediate Results : Changes in prompt structure yield immediate changes in outputs. so it can be Fast and lightweight way to adapt LLMs for new tasks- Cons:
Inconsistency : Results can be unpredictable and highly dependent on the exact wording of the prompt. And it can require extensive trial-and-error to find effective promptsSkill-Intensive : It requires a deep understanding of how the model responds to different prompts.Scalability Issues : For large-scale applications, crafting individual prompts can be impractical.No extension of LLM Core : : It does not expand the core capabilities of the LLM itself- Pros:
Extending LLM Core capability : It directly augments core knowledge and capabilities of the LLMCustomization : It allows for tailoring the model to specific tasks or datasets.Improved Performance : Can significantly improve performance on the targeted tasks.Control Over Outputs : Enables more predictable and controlled outputs compared to base models.- Cons:
Resource-Intensive : Requires additional data, computational resources, and time to retrain or fine-tune.Risk of loosing existing capability : Risk of losing some existing general knowledge/capabilitiesRisk of Overfitting : Especially if the fine-tuning data is not diverse enough or too small.Maintenance : Over time, the model might need retraining as the domain data evolves or goals change.- Pros:
Dynamic Knowledge : Can pull in the most recent data or domain-specific information from external sources.Versatility : Combines the generative abilities of LLMs with the retrieval of up-to-date or specialized information.Improved Accuracy : Can improve factual accuracy and relevancy in responses.- Cons:
Complexity : Adds additional layers of complexity in combining retrieval and generation mechanisms.Dependence on External Data : The quality of outputs is highly dependent on the quality and relevance of the retrieved documents.Latency : Can introduce additional latency due to the retrieval process, especially if the external database is large or the retrieval process is complex.
Is there any single best solution ?
NO. Which one is the best solution to extend a fundamental LLM model depends on your use case. I have read many articles and watched a lot of YouTube dealing with different ways of extending a LLM model, and I have tried myself as well. The conclusion is the best solution is different depending on use case and many expert say eventually we would need to use all the possible technology (i.e, Fine Tunning, RAG, Prompt Engineering) to make the best use of the technology. So important thing is to understand exact reason of why you want to extend an existing LLM model and to understand the pros and cons of each technology.
Here goes a list of questions (check list) that would help you with determine which techniques to go with.
Understand the Nature of Your Application - What is the primary function of the LLM in your application? (e.g., answering general queries, providing specialized knowledge, generating creative content)
- Is your application domain-specific or does it require general knowledge? (e.g., medical, legal, entertainment)
Consider the Data Availability and Quality - Do you have access to high-quality, domain-specific datasets for training?
- Is your data static or does it frequently update?
Evaluate the Need for Up-to-Date Information - How critical is it for your application to have the most current information?
- Does your use case involve dynamic content that changes regularly? (e.g., news, market data)
Assess the Resource Availability and Constraints - What computational resources are available for training or fine-tuning?
- Do you have the expertise and time to manage a fine-tuning process?
Determine the Flexibility and Customization Needs - How much control do you need over the model's responses?
- Is there a need for the model to adhere to specific guidelines or styles?
Evaluate the Importance of Context and Depth in Responses - Are detailed, context-rich responses important for your application?
- Does your application require deep, multi-step reasoning or external knowledge retrieval?
Consider the Scalability and Maintenance - How scalable does your solution need to be?
- What are your long-term plans for maintaining and updating the model?
Following is a few guideline cases based on the checklist mentioned above.
If you require domain-specific knowledge and have quality data available for training : Consider Fine-Tuning.If staying current with the latest information is critical and your content is dynamic : Lean towards Retrieval-Augmented Generation (RAG).If you need quick deployment, have limited resources, or your application requires creative use of language within the model's existing knowledge base : Prompt Engineering might be the most suitable.
Challenges of RAG
Retrieval-Augmented Generation (RAG) offers significant advantages for enhancing Large Language Models (LLMs), but it also comes with its own set of challenges. Understanding and addressing these challenges is crucial for the effective deployment and use of RAG models in various applications. Continuous improvements in retrieval algorithms, better integration techniques, and advancements in ethical AI practices are essential to mitigate these challenges.
Quality of Retrieved Information: Relevance : Ensuring that the external documents or information retrieved are relevant to the query is crucial. Irrelevant or tangentially related information can lead to inaccurate or misleading responses.Accuracy : The retrieved information must be accurate and trustworthy. RAG models can inadvertently propagate misinformation if the source data is incorrect.Integration of Retrieved Data: Seamless Integration : Combining the retrieved information with the model's pre-existing knowledge in a coherent and contextually appropriate manner is complex.Handling Conflicting Information: The model may retrieve multiple sources with conflicting information, making it challenging to generate a coherent and accurate response.Latency and Computational Efficiency: - RAG models can be slower than standard LLMs because they need to retrieve information in real-time. This can be a significant challenge for applications requiring quick response times.
- The computational overhead for retrieval and processing of external information can be substantial, especially for large-scale applications.
Dependency on External Sources: Availability : The model's performance is partly dependent on the availability and accessibility of external data sources.Changes in Sources : If the external sources update or change their content, it can affect the consistency and reliability of the model's responses.Maintaining Up-to-Date Knowledge: - Continuously ensuring that the external sources are current and relevant is challenging, especially in rapidly evolving fields.
Complexity in Training and Tuning: - Training and fine-tuning RAG models can be more complex than traditional LLMs due to the additional layer of information retrieval and integration.
Scalability: - Scaling RAG models for widespread or high-demand applications can be challenging due to the additional computational requirements for real-time data retrieval.
Challenges of Fine-Tuning
Fine-tuning Large Language Models (LLMs) also has its own challenges. These challenges highlight the importance of careful planning, resource allocation, and continuous monitoring when fine-tuning LLMs. Despite these challenges, fine-tuning remains a powerful tool for customizing LLMs to specific tasks and domains.
Data Requirements: Quality and Quantity of Data : Fine-tuning requires a substantial amount of high-quality, labeled data. Obtaining such data can be challenging, especially for niche or specialized domains.Representativeness : The data used for fine-tuning needs to be representative of the tasks the model will perform, which can be difficult to ensure.Risk of Overfitting: - Fine-tuning on a specific dataset, especially a small one, can lead the model to overfit to that data. This means it might perform well on similar data but poorly generalize to new, unseen data.
Catastrophic Forgetting: - When an LLM is fine-tuned on new data, there's a risk that it will "forget" what it learned during its initial training. This is particularly problematic if the new data is very different from the original training data.
Resource Intensive: Computational Resources : Fine-tuning requires significant computational resources, which can be a barrier, especially for smaller organizations or individual researchers.Expertise : It also requires technical expertise in machine learning and natural language processing to effectively implement.Model Drift: - Over time, as the domain of application evolves, the fine-tuned model may become less accurate if it's not continually updated, a phenomenon known as model drift.
Dependency on Domain Expertise: - Effective fine-tuning often requires domain-specific expertise to ensure that the model understands and generates domain-relevant and accurate responses.
Scalability and Maintenance: - Maintaining and updating a fine-tuned model can be resource-intensive. As the field or data changes, the model may need retraining or further fine-tuning.
Learn with YouTube and AI
With the widespread of AI since early 2023, I have tried a little bit of new approach of study/learning utilizing various AI solutions. In this section, I am trying to pick up some of the YouTube materials that looks informative (at least) to me. The contents that I am sharing in this section is created as follows.
- Watch the full contents of YouTube material myself
-
NOTE : This is essential since there are a lot of visual material that cannot be shared by the summary and also some details not captured by summary. If you skip this step, nothing would go through your brain... it would just go through YouTube and directly through AI. Then, AI would learn but you would not :) - Get the transcript from YouTube (As of 2023, YouTube provide the built-in function to generate the transcript for the video)
- Copy the transcribe, save it into a text file. Paste the text file into chatGPT (GPT 4) and requested summary (NOTE : If you do not subscribe chatGPT paid version, you may try it with claude ai.)
|
A Survey of Techniques for Maximizing LLM Performance |
Now let's start .....
This is a presentation given at OpenAI's first developer conference. The speakers, John Allard and Colin, discuss techniques to maximize the performance of Large Language Models (LLMs), particularly focusing on fine-tuning methods and optimization strategies. They detail how developers can leverage various techniques like prompt engineering, retrieval-augmented generation, and fine-tuning to solve specific problems more effectively using LLMs. The presentation goes into examples of how these methods are applied in practice, offering insights into the iterative and often non-linear nature of optimizing LLMs. The talk concludes with the speakers encouraging the audience to explore these techniques further and apply them in their own work.
The presenters discussed the importance of maximizing performance in Large Language Models (LLMs) for solving real-world problems. They highlighted fine-tuning, retrieval-augmented generation, and prompt engineering as key techniques.
OpenAI's recent advancements in fine-tuning techniques were shared, including Turbo fine-tuning, continuous fine-tuning, and a full UI for fine-tuning within the platform.
3.5 Turbo Fine-Tuning :Launched in August, Turbo fine-tuning was well-received by the developer community. It represents a significant enhancement in the fine-tuning process, allowing for quicker and more efficient training of LLMs on specific tasks or datasets.Fine-Tuning on Function Calling Data :This feature involves fine-tuning models on data related to function calls, enhancing the model's ability to understand and generate code or responses involving API calls or other function-driven tasks.Continuous Fine-Tuning :Continuous fine-tuning allows developers to take an already fine-tuned model and further train it on new data. This iterative process is crucial for applications where the model needs to adapt to new information or changing data over time.Full UI for Fine-Tuning within the Platform :OpenAI introduced a comprehensive user interface for fine-tuning on their platform, making it more accessible and easier for developers to fine-tune models. This UI aims to
Despite the proliferation of frameworks and tools, optimizing LLMs remains challenging. The presentation emphasized the difficulty of separating signal from noise and the non-linear nature of performance optimization.
Hard to Separate Signal from Noise It's challenging to discern what is genuinely improving the model's performance versus what might be coincidental or noise in the data. Diagnosing the root cause of an issue in LLMs is difficult because of the complexity and black-box nature of these models.Abstract and Difficult Performance Measurement : Quantifying performance and improvements is tricky, especially when dealing with abstract or subjective tasks. It's not always clear how much of a problem exists or the magnitude of that problem due to the qualitative aspects of LLM outputs.Choosing the Right Approach for Identified Problems : Even if the problem is identified and understood, deciding on the right method or combination of methods (prompt engineering, retrieval-augmented generation, fine-tuning) to address it is complex. The decision heavily depends on the specific use-case, and there's rarely a one-size-fits-all solution.Non-linear Nature of Optimization : Optimization is not a straightforward path with LLMs; improvements in one area might lead to unexpected regressions in another. It often requires an iterative and experimental approach, where you might need to circle back to earlier techniques or try different combinations of methods.Reliance on Evaluation Frameworks: There is a heavy reliance on developing or using robust evaluation frameworks to measure performance effectively and guide the optimization process. This is essential to understand if the changes being made are actually leading to improvements and not just random variations
The speakers discussed the different phases of optimization: starting with prompt engineering, moving to retrieval-augmented generation, and finally, to fine-tuning. They stressed that optimization is not always linear and depends heavily on the specific problem
Optimization is Non-linear: - Emphasized that improving LLM performance is not a straightforward, linear process. It often requires moving between different techniques and revisiting previous strategies based on the problem's nature and encountered challenges.
Initial Stage - Prompt Engineering: - Identified as the best starting point for optimizing LLMs. It's accessible and allows for rapid iteration and learning.
- It's both a context and LLM optimization technique but has scalability limits.
- Prompt engineering is particularly useful for initial testing and establishing a performance baseline.
Context Optimization - Retrieval-Augmented Generation (RAG): - If the problem requires more context or domain-specific information, the progression moves towards RAG.
- RAG introduces new, relevant information to the model and can help in reducing hallucinations or inaccuracies by controlling the content fed into the model.
- While adding richness in context, RAG is not suitable for embedding broad domain understanding or significantly reducing token usage.
LLM Optimization - Fine-Tuning: - If the model needs more consistent instruction following or a more specialized understanding, fine-tuning is the approach.
- It involves continuing the training process on a smaller, more domain-specific dataset, making the model more suited for particular tasks or improving its overall performance.
- Fine-tuning can drastically transform the capabilities of a model but requires careful consideration of data quality, training approach, and potential risks like overfitting or catastrophic forgetting.
Iterative Optimization Journey: - The journey often starts with prompt engineering, then moves to assess whether the issue is about context (RAG) or instruction following (fine-tuning).
- It was noted that often, both RAG and fine-tuning are needed, and they stack additively to address complex problems.
- The optimization process is iterative, requiring ongoing evaluation and adjustments based on performance metrics and the model's outputs.
Techniques for effective prompt engineering were discussed, including writing clear instructions, splitting complex tasks into simpler subtasks, and systematically testing changes.
Writing Clear Instructions: - Importance of crafting unambiguous and direct instructions to guide the model's responses.
- Example given in the presentation highlights the need for specificity to achieve desired results.
Splitting Complex Tasks into Simpler Subtasks: - Breaking down complex tasks into smaller, manageable parts for the model to handle sequentially.
- This approach helps the model make predictions for each subunit or subtask, improving overall task execution.
Giving GPTs Time to Think: - Employing techniques like the REACT framework, where the model writes out its reasoning steps to reach a conclusion.
- This approach is especially beneficial for complex logical reasoning tasks.
Systematic Testing of Changes: - The necessity of systematically measuring and evaluating the impact of any changes made to prompts.
- It addresses the common issue where changes are made rapidly without understanding their effectiveness or direction.
Extending to Reference Text or External Tools: - As the next step in prompt engineering, introducing reference texts or external tools to improve context understanding.
- This leads into the territory of retrieval-augmented generation (RAG)
The utility of RAG in introducing new information and reducing hallucinations was discussed. Success stories and a cautionary tale highlighted the iterative nature of optimizing with RAG.
Introducing New Information: - RAG allows models to access external, domain-specific content, effectively updating its knowledge base for the specific query at hand.
- It serves as a method to introduce new information to the model that wasn't part of its original training data.
Reducing Hallucinations by Controlling Content: - By specifying the content that the model should use to generate responses, RAG can help in minimizing the generation of false or irrelevant information, a phenomenon often referred to as "hallucinations."
Typical Use Case - Content Constraints: - A common application is instructing the model to strictly use the content provided to it for answering questions, thereby aligning the model's outputs more closely with desired or accurate information.
Not Suitable for Broad Domain Understanding: - RAG is not effective for instilling an understanding of a broad domain such as law or medicine. It's more about providing specific, relevant snippets of information rather than a comprehensive understanding.
Not Ideal for Teaching New Language Format or Style: - Teaching a model a new language format or style typically falls under the domain of fine-tuning rather than RAG. RAG is more about content than style or methodological learning.
Increasing Token Usage: - As RAG involves adding external content, it inevitably leads to an increase in the number of tokens the model processes, which can impact cost and latency.
Success Story - Iterative Improvement: - An example was provided where a RAG pipeline was used to answer user questions using two different knowledge bases. Initial accuracy was at 45%, and through iterative testing and improvement, including re-ranking and classification strategies, the accuracy was eventually improved to 98%.
Cautionary Tale - Dependence on Quality of Retrieved Content: - Another story shared was a reminder of RAG's reliance on the quality and relevance of the retrieved content. If the retrieval process is flawed or the content is not well-aligned, it can lead to incorrect or suboptimal responses. This emphasizes the need for careful construction and continual evaluation of the RAG component.
The presentation highlighted fine-tuning as a transformative process for LLMs, allowing for specialized performance in specific domains. A success story from Canva demonstrated the effectiveness of fine-tuning in generating structured design guidelines.
Transformative Process for LLMs: - Fine-tuning is described as a transformative process that adapts a general model to be more effective for specific tasks or domains.
Specialized Performance in Specific Domains: - The utility of fine-tuning lies in its ability to make LLMs perform exceptionally well in particular domains or tasks that may not be covered in the original, broad training.
Benefits of Fine-Tuning: - Fine-tuning can allow for superior performance levels that might be unachievable with base models or through other techniques.
- Fine-tuned models are often more efficient, requiring simpler prompts and yielding faster responses.
Efficiency in Interaction: - Fine-tuned models require less complex prompting, meaning that each interaction is quicker and more cost-effective.
Domain-Specific Adaptation: - Fine-tuning modifies a general model to understand and perform well on the intricacies and unique aspects of a specific domain.
Process Involves: - The process involves training an existing model further on a smaller, more specialized dataset relevant to the desired task.
Challenges and Considerations: - While fine-tuning can drastically improve performance, it also introduces challenges such as the risk of overfitting and ensuring that the new training data is of high quality.
Iterative and Complex: - The fine-tuning process is iterative and complex, often requiring multiple rounds and careful monitoring to ensure improvements are genuine and useful.
Reference
- Full Fine-Tuning, PEFT, Prompt Engineering, and RAG: Which One Is Right for You? - deci (Sep 2023)
- Differences Between RAG and Fine Tuning - LinkedIn (Oct 2023)
- RAG Vs Fine-Tuning Vs Both: A Guide For Optimizing LLM Performance - Galileo (Oct 2023)
- Forget RAG: Embrace agent design for a more intelligent grounded ChatGPT! - Medium (Nov 2023)
YouTube
- A Survey of Techniques for Maximizing LLM Performance - OpenAI (Nov 2023)
- AWS re:Invent 2023 - Build your first generative AI application with Amazon Bedrock (AIM218) - AWS Events(Nov 2023)
- AWS re:Invent 2023 - Use RAG to improve responses in generative AI applications (AIM336) - AWS Events(Nov 2023)
- OpenAI's new ASSISTANTS API: How To Create GPTs - code_your_own_AI (Nov 2023)
- After RAG, Vector & GPT Store: NEW AI Breakthrough UNFOLDS - code_your_own_AI (Nov 2023)
- RAG's Collapse: Uncovering Deep Flaws in LLM External Knowledge Retrieval - code_your_own_AI (Nov 2023)
- Stanford CS229 I Machine Learning I Building Large Language Models (LLMs) - Standford Online (2024) ***