|
LLM for Telco
We all know that it is tricky and painful to read specifications in telco. We all know that LLM (especially chatGPT and a few others) has shown its capability of doing great job where we are suffering. Then can LLM save us from the pain and agony with reading telco specs (especially 3GPP specification) ?
Understanding telecommunication specifications, especially those from the 3GPP, can be very difficult. These documents are often full of technical words and complicated ideas that are hard to follow. Everyone who works with these documents, from experienced engineers to those new to the field, knows how frustrating it can be to understand them. I've certainly had my own difficulties, especially when trying to find specific information for planning networks or solving problems between
different equipment. Even simple tasks, like finding out which frequency bands a device uses or understanding the details of a specific communication method, can take a lot of time.
However, a new kind of tool, powered by Large Language Models (LLMs) like ChatGPT, is showing promise in solving this problem. These advanced AI models are very good at understanding and processing complex information. This makes us wonder: Can LLMs be the key to understanding the complicated information in telecom specifications? Based on the various research being done in this area and my personal experience as well, I think LLMs can greatly simplify how we use these important
documents, although they do have some limitations.
In this note, we'll look at how LLMs can change the way we work with these important documents. We'll discuss the specific problems that telecom specifications cause, examine how LLMs can help with these problems, and talk about the possible advantages and disadvantages of this new technology. Join us as we explore whether LLMs can truly guide us through the complexities of telecom standards, making the process easier, faster, and more productive.
Large Language Models (LLMs) can bring many advantages to the analysis of telecom specifications:
LLMs can do many things automatically in the telecom industry. They can make short summaries of long technical documents, answer questions about how things work, and even write descriptions of communication protocols. This automation can help telecom workers in many ways.
-
LLMs can automate tasks like summarizing technical documents. This means they can create shorter versions of long documents.
-
LLMs can answer questions about the specifications.
-
LLMs can create descriptions of how communication protocols work.
-
This automation can be used to help with troubleshooting, network operations, and software development.
-
LLMs can also be used to create models of networks and help with network development.
-
In customer service, LLMs can help solve problems more efficiently, leading to happier customers.
-
By automating these tasks, telecom professionals have more time to focus on harder problems.
LLMs optimize workflows by analyzing patterns and providing actionable insights. They help improve areas like data management, network routing, and customer engagement, enabling telecom companies to deliver better services, reduce downtime, and make efficient use of resources.
-
Data Management: LLMs can analyze large datasets, organize information, and provide insights that help in decision-making and process improvement.
-
Network Routing: By studying traffic patterns, LLMs can recommend adjustments to optimize network performance and reduce congestion.
-
Customer Engagement: LLMs can personalize interactions and responses, improving customer satisfaction and fostering loyalty.
-
Downtime Prevention: LLMs can predict potential operational issues and suggest preventive measures, minimizing disruptions.
-
Resource Allocation: LLMs identify opportunities for automation and efficient use of manpower and technology, leading to cost savings and enhanced productivity.
LLMs analyze trends and usage patterns to help telecom providers allocate resources effectively. By directing investments to where they are most needed, LLMs ensure optimal performance and cost efficiency, enabling telecom companies to deliver better services at competitive rates.
-
Trend Analysis: LLMs identify usage patterns and predict demand, allowing for proactive resource planning and investment.
-
Cost Efficiency: By optimizing resource allocation, LLMs reduce unnecessary expenses, improving overall operational cost-effectiveness.
-
Performance Optimization: LLMs ensure that critical areas receive adequate resources, enhancing network reliability and performance.
-
Scalable Solutions: LLMs adapt resource recommendations based on changing demand, making it easier to scale operations without waste.
-
Competitive Pricing: By minimizing costs and improving efficiency, LLMs enable telecom companies to offer more affordable services to their customers.
LLMs can make finding and understanding information from telecom documents more accurate. They have a lot of knowledge and can understand the difficult technical words used in those documents . LLMs can even check their own work when they are taking information from protocols, which makes the results more reliable .
-
LLMs can make information extraction and analysis more accurate. They have a large knowledge base and can understand complex technical language.
-
LLMs can check their own work when extracting information about protocols. This leads to more reliable results.
-
In case of most RFC, Pre-trained LLMs can be used without needing to be fine-tuned. This makes them even more accurate.
-
LLMs can improve network security by analyzing network traffic and finding unusual activity.
-
LLMs can achieve very good prediction performance with low training and inference costs. This means they can be trained quickly and cheaply, and they can make predictions quickly.
-
This leads to more reliable and efficient network operations and development processes.
LLMs can help telecom companies discover new information and better understand their customers. They can find hidden patterns in technical documents, which helps experts understand the rules and ways things work in the telecom world .
-
LLMs can help find hidden patterns and insights in technical specifications. This helps us understand telecom standards and protocols better.
-
They can understand information beyond just text, including code and diagrams. This makes their knowledge discovery even better.
-
LLMs can be used to improve customer service and support. They can analyze customer data and provide personalized recommendations.
-
LLMs can also make chatbots and voice assistants more accurate and natural. This makes them better at understanding and responding to user requests.
-
These discoveries can lead to new ideas and better decision-making in the telecom industry.
LLMs address scalability challenges by leveraging AI to analyze data, optimize resources, and adapt services dynamically. This ensures telecom providers can efficiently meet growing market demands.
-
Forecasting Market Trends: LLMs analyze market data and consumer trends, helping telcos predict demand and plan service scaling.
-
Rapid Resource Deployment: LLMs automate troubleshooting and resource optimization, enabling quick responses to market changes and customer growth.
-
Dynamic Service Adaptation: LLMs facilitate real-time adjustments to services based on customer usage and network requirements.
-
Integrating Advanced Technology: LLMs process large data volumes efficiently, assisting in the seamless scaling of new technologies in telecom operations.
There is a wide range of use cases for LLM in telecommunications, and it goes far beyond what we might have expected. It’s not just about summarizing or interpreting language anymore. LLMs are changing how we solve problems in telecom by tackling challenges like setting up networks, optimizing resources, predicting trends, and improving security. They can automate time-consuming tasks like fixing network issues or writing code and help classify and organize information in complex
systems. LLMs are powerful because they can learn from different types of data, work with images and numbers alongside text, and provide useful answers quickly. These features not only make telecom operations faster and easier but also open the door to exciting new ideas for the future of telecom networks, especially as we move toward advanced technologies like 6G.
In this section, I will go through a list of applications mentioned in various research papers and articles. (NOTE : Initial list is mostly based on Large Language Model (LLM) for Telecommunications: A Comprehensive Survey on Principles, Key Techniques, and Opportunities and I will keep adding more items or details as I read more)
LLMs can generate telecom-related content such as troubleshooting reports, standard drafts, network configurations, and domain knowledge summaries.
LLM Advantage:
-
Automates time-consuming tasks.
-
Reduces human effort in writing, revising, and planning.
-
Handles multi-step planning with structured action sequences.
Example:
-
Generating network troubleshooting reports based on past trouble tickets
-
Telecom-specific code generation (e.g., Verilog for OpenWiFi projects).
Challenges:
-
Training LLMs on telecom-specific datasets due to accessibility and privacy issues.
-
Potential for incorrect or misleading generation, requiring extensive verification.
LLMs assist in categorizing and detecting network issues, traffic types, or user behaviors.
LLM Advantage:
-
Supports zero-shot classification without extensive task-specific training.
-
Combines text, image, and signal classification for holistic network insights.
Example:
-
Classifying network attacks, such as Distributed Denial of Service (DDoS).
-
Image-based blockage prediction in mmWave beamforming scenarios.
Challenges:
LLMs improve network resource allocation, load balancing, and performance tuning through verbal reinforcement learning or automated heuristic design.
LLM Advantage:
-
Simplifies complex tasks by converting them into a specific algorithm (e.g, Markov Decision Process (MDP)).
-
Automates reward function design for reinforcement learning.
Example:
Challenges:
LLMs can predict time-series data (e.g., network traffic or beamforming requirements) and multimodal data trends.
LLM Advantage:
-
One-model-for-all prediction: LLMs generalize across various time-series tasks after pre-training.
-
Supports multi-modal predictions combining textual, visual, and numerical inputs.
Example:
Challenges:
LLMs summarize, interpret, and generate telecom-specific knowledge or code to streamline operations.
LLM Advantage:
-
Refactors, validates, and enhances existing telecom code.
-
Improves accessibility of telecom knowledge for researchers and practitioners.
Example:
Challenges:
LLMs automate network setup, provisioning, and optimization by translating high-level intents into low-level configurations.
LLM Advantage:
Example:
Challenges:
LLMs aid in detecting, diagnosing, and resolving network faults.
LLM Advantage:
Example:
Challenges:
LLMs handle complex telecom planning tasks, such as resource management and service orchestration.
LLM Advantage:
Example:
Challenges:
LLMs assist in identifying, analyzing, and mitigating security threats.
LLM Advantage:
Example:
Challenges:
-
High false positive rates in anomaly detection.
-
Ensuring scalability for large, distributed networks.
LLMs can assist in diagnosing and resolving network anomalies by analyzing historical troubleshooting tickets, understanding equipment malfunctions, and proposing solutions.
LLM Advantage:
-
Enhances troubleshooting efficiency by leveraging historical data.
-
Reduces the time required for anomaly diagnosis.
-
Predicts resolution timelines based on specific fault types and equipment details.
Example:
Challenges:
LLMs can assist in building and optimizing network models by selecting relevant features and suggesting relationships between network parameters.
LLM Advantage:
-
Reduces the need for extensive manual feature selection.
-
Helps identify relationships between network parameters.
-
Accelerates the development of optimization models.
Example:
-
Creating a model for energy consumption prediction in Base Stations (BS).
-
Identifying critical features like frequency, load, and power configurations.
Challenges:
Deep Dive Example :
In a test scenario, GPT-3.5 was tasked with creating a model to estimate energy consumption in a network of 90 single-carrier base stations (BSs) using 12 features, such as BS location, frequency, and load.
NOTE : This example came from Large Language Models for Telecom: Forthcoming Impact on the Industry
The LLM identified five relevant features without using data samples, producing an initial model based on a weighted sum of inputs. However, the model failed to capture the interaction between load and maximum transmit power, resulting in a 7.8% error rate. After providing additional
telecom-specific context, GPT-3.5 revised its model, correctly incorporating the interaction by multiplying load and maximum transmit power. This reduced the error to 3%, aligning the model with observed trends as shown below.
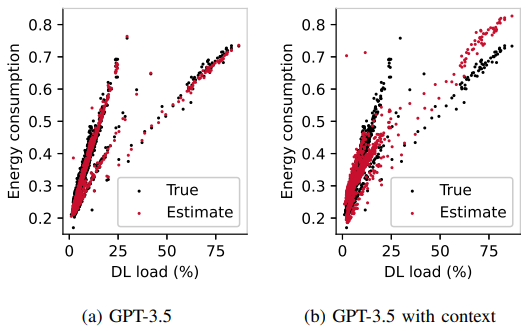
Image Source : Large Language Models for Telecom: Forthcoming Impact on the Industry
The figure shown below compares energy consumption estimates across different models:
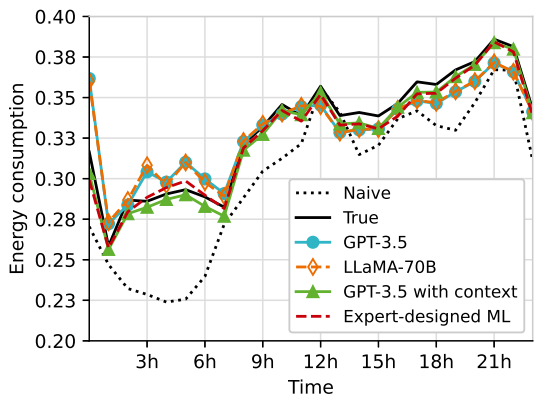
Image Source : Large Language Models for Telecom: Forthcoming Impact on the Industry
-
Naive Model: Averaged hourly energy consumption, resulting in a 12% error due to its lack of domain knowledge.
-
GPT-3.5 Models: Initial and context-aware versions, achieving error rates of 7.8% and 3%, respectively.
-
Expert-Designed ML Model: Achieved the best performance with a 2.3% error by addressing complex scenarios.
-
LLaMA-70B: Produced a model similar to GPT-3.5's initial version, with a 7.6% error, but failed to correct its limitations even with added context.
The results emphasize the importance of context in improving LLM-based models and highlight the potential of LLMs like GPT-3.5 to approach expert-level performance in network optimization tasks.
Despite the potential benefits, applying LLMs to the analysis of telecommunication specifications like 3GPP and RFC documents is not without its challenges. These challenges stem from various factors, including limitations in the LLMs themselves, the nature of the source material, and the complexities of the telecom domain
A fundamental challenge in leveraging LLMs for telecom specification analysis is the availability of suitable data . Effective training and evaluation of these models rely on comprehensive and high-quality datasets specifically related to the telecommunications domain . This data needs to encompass the unique language, terminology, and complexities of telecom standards and operations . However, much of this data is often proprietary, held by companies, or limited in scope,
hindering the development of robust LLM-based solutions
-
To train and evaluate LLMs, we need comprehensive and high-quality telecom-specific datasets. This means we need large amounts of good quality data related to telecommunications.
-
However, these datasets are often owned by companies and not shared publicly, or they might be limited in scope. This makes it hard to develop good LLM-based solutions.
-
It is also important to protect data privacy and follow regulations like GDPR (General Data Protection Regulation). This can be a challenge when fine-tuning LLMs for telecom tasks.
Telecom specifications, like those from 3GPP and RFC documents, are often unclear and difficult to understand, even for human experts. This poses a major challenge for LLMs. Here's why:
-
Unclear Language: These documents often use natural language, which can be vague and open to different interpretations.
-
Missing Information: Some parts of the documents might be missing or not fully explained, leading to gaps in understanding.
-
Contradictions: Different sections of a document might contradict each other, causing confusion and making accurate analysis difficult.
-
Changing Standards: Telecom specifications are constantly being updated, with new versions and changes that can introduce inconsistencies.
This lack of clarity in the source material makes it hard for LLMs to:
-
Accurately extract information.
-
Understand how different parts of the specification relate to each other.
-
Provide consistent and reliable answers.
It can also lead to "hallucinations," where the LLM generates incorrect or nonsensical information because it misinterprets the unclear text.
3GPP specifications are not just walls of text. They incorporate various elements like mathematical symbols, equations, tables, and diagrams, which are often interconnected and require a deeper understanding than simply extracting information from the text .
Here's why this poses a challenge for LLMs:
-
Limited Multimodal Understanding: While LLMs excel at processing text, their ability to understand and interpret mathematical symbols, equations, and tables is still under development. They may struggle to extract the meaning conveyed through these non-textual elements and connect them with the surrounding text.
-
Complex Relationships: Information in 3GPP documents is often conveyed through the interplay of text, formulas, and tables. For example, a table might define parameters used in an equation, which is then explained in the text. LLMs need to understand these complex relationships to accurately interpret the information.
-
Lack of Training Data: Most LLMs are trained on text-heavy datasets, with limited exposure to the diverse multimodal content found in 3GPP specifications. This lack of training data can hinder their ability to effectively analyze these documents.
To overcome this challenge, researchers are exploring several avenues:
-
Multimodal LLMs: Developing LLMs that can process and understand different modalities, such as text, images, and mathematical symbols, is crucial.
-
Data Augmentation: Creating synthetic datasets that incorporate mathematical expressions and tables can help train LLMs to better understand these elements.
-
Hybrid Approaches: Combining LLMs with other AI techniques, such as computer vision for diagram interpretation and symbolic AI for equation solving, can enhance their ability to analyze 3GPP specifications.
Often we feeding an entire specification document(e.g, an entire 3GPP spec document) into an LLM prompt, while seemingly straightforward, can lead to several challenges:
- Context Window Limits: LLMs have a limited context window, meaning they can only process a certain amount of text at once. 3GPP specifications are often extensive, exceeding these limits. This forces the LLM to truncate the document, potentially losing crucial information and context .
- Information Overload: Presenting the entire document can overwhelm the LLM with irrelevant information, making it harder to focus on the specific details needed to answer the question. This can lead to less accurate and less relevant responses .
- Lack of Focus: Without specific guidance, the LLM may struggle to identify the most relevant sections within the document, potentially missing crucial details or misinterpreting the information .
- Ambiguity and Inconsistency: As mentioned earlier, 3GPP specifications can contain ambiguous language, incomplete information, and even contradictions. Providing the entire document without clear guidance can exacerbate these issues, leading to unreliable analysis.
Cross-referencing is a significant challenge for LLMs in interpreting telecom standards, as these documents rely heavily on interlinked sections to convey technical details. Despite using entire documents or advanced techniques like Retrieval-Augmented Generation (RAG), LLMs often struggle to accurately resolve these references, leading to incomplete or erroneous interpretations.
- Complexity of Cross-Referencing: Accurately resolving cross-references is crucial for interpreting telecom standards, as these documents often rely on interlinked sections to convey technical intricacies.
- LLM Limitations: Despite using entire documents or advanced techniques like Retrieval-Augmented Generation (RAG), LLMs frequently fail to interpret and integrate cross-references correctly.
- Impact on Interpretations: The inability to handle cross-references effectively undermines LLMs' ability to provide precise and comprehensive analyses of structured telecom documentation.
- Example of the Challenge:
- To explain 36.212 Section 5.3.1.3 (Rate Matching), the LLM must refer to related sections, such as:
- 36.212 Section 5.4.1.2
- 36.211 Section 6.6.1
- However, LLMs often fail to follow and integrate these contextual dependencies, leading to incomplete or erroneous interpretations.
- Need for Advanced Mechanisms:
- Addressing this challenge requires developing advanced mechanisms for managing and interpreting interconnected textual data, enabling LLMs to better handle the complexities of cross-referencing in telecom standards.
A notable challenge is the performance degradation of smaller LLMs (e.g., Llama-3B) when tasked with generating long, detailed responses. While they may perform adequately for short and concise replies, their limitations become evident with larger context windows.
- Limited Capacity: Smaller models lack the parameter space required to encode and process complex relationships and maintain coherence over longer contexts.
- Repetition and Redundancy: When attempting longer outputs, these models often default to repeating initial sentences or phrases due to their inability to synthesize and expand on prior context.
- Training Bias: Fine-tuned LLMs optimized for concise answers may struggle when required to deliver structured, multi-paragraph outputs.
This challenge is exacerbated by the need for detailed and accurate explanations in a technical domain like telecommunications, where precision and depth are crucial.
While LLMs have shown impressive performance in coding tasks, their ability to generate signaling messages like RRC (Radio Resource Control) and NAS (Non-Access Stratum) messages in telecommunications remains limited. This discrepancy arises from several key factors:
- Complexity of Signaling Messages: Signaling messages are not simply code; they are highly structured data packets with specific formats and intricate dependencies defined by telecom standards . These messages often involve complex encoding and decoding processes, requiring precise knowledge of protocol specifications and intricate state machines.
- Lack of Specialized Training Data: LLMs typically excel in domains with abundant training data. However, datasets specifically focused on generating telecom signaling messages are scarce. This limits the LLM's ability to learn the nuances of message construction and the intricate relationships between different message fields .
- Need for Domain Expertise: Creating accurate signaling messages requires deep domain expertise in telecommunications protocols and standards. LLMs, even with vast general knowledge, may lack the specific understanding needed to generate valid and contextually appropriate messages .
- Limited Reasoning and Inference: Generating signaling messages often involves reasoning about network conditions, user states, and complex scenarios. LLMs, while improving in reasoning abilities, may still struggle with the intricate logic and decision-making required for accurate message generation .
- Challenges in Evaluating Performance: Evaluating the correctness of generated signaling messages is not straightforward. It requires specialized tools and domain expertise to verify that the message adheres to the protocol specifications and achieves the intended functionality .
While Retrieval-Augmented Generation (RAG) offers a powerful approach to enhance LLMs for telecom specification analysis, it also presents unique challenges . Here are some key challenges specific to RAG in this domain:
-
Sensitivity to Hyperparameters: The performance of RAG models can be significantly affected by the choice of hyperparameters, such as the number of retrieved documents, the similarity threshold for retrieval, and the weighting of retrieved documents in the LLM's input . Finding the optimal hyperparameters for telecom specifications requires careful tuning and experimentation.
-
Vague User Queries: Telecom specifications often involve complex technical language and abbreviations. When user queries are vague or use imprecise terminology, the RAG system may struggle to retrieve the most relevant information . This can lead to inaccurate or incomplete answers.
-
Sensitivity to Prompt Quality: The quality of the prompts used to guide the LLM in generating responses can significantly impact the accuracy and relevance of the output . Crafting effective prompts for complex telecom queries requires expertise and careful consideration of the specific task.
-
Handling Verbose or Misaligned Responses: Initial RAG implementations may produce overly verbose answers or adopt a tone that doesn't align with the technical context . Prompt tuning and other techniques are needed to refine the LLM's output and ensure it meets the specific needs of telecom specification analysis.
-
Retrieving Context from Multiple Documents: Relevant information may be spread across multiple documents, making it difficult for the retrieval system to gather all the necessary context . Advanced retrieval methods and techniques like HyDE are being explored to address this challenge.
Data Privacy and Security: RAG systems in telecommunications often handle sensitive customer and network information . Ensuring data privacy and security is crucial for building trust and complying with regulations.
Training LLMs to work well with telecom specifications requires a lot of computer power and special knowledge. To make these LLMs perform their best, we often need to adjust them using specific data from the telecom field. This means teaching the LLM to understand the special words and ideas used in telecom.
One difficulty is using these LLMs in telecom systems, especially on small devices or in 5G stations. These places may not have a lot of computer power, so we need to use it carefully.
- High Computational Demands: Training LLMs for telecom specifications requires significant computing power and specialized expertise, making the process resource-intensive.
- Fine-Tuning for Telecom: To achieve optimal performance, LLMs often need to be fine-tuned with telecom-specific data. This involves teaching the model to understand the unique terminology and concepts in the telecom domain.
- Deployment Challenges: Deploying LLMs in telecom environments, such as edge devices or 5G base stations, is challenging due to limited computational resources. Efficient resource management is critical in these scenarios.
- Customer Service Data Utilization: Using customer service chat data for LLM fine-tuning comes with challenges, including:
- Ensuring data quality.
- Mitigating biases in the training data.
- Maintaining user privacy.
- Efficiently managing resources for data collection, processing, and anonymization.
It can be hard to understand how LLMs make decisions, especially when they are working with complicated technical information . LLMs are like very complex machines with many parts. It can be difficult to see how all the parts work together to produce a result . This can make people less trusting of the LLM, especially when they need to make important decisions based on the LLM's analysis.
- Complex Decision-Making: Understanding how LLMs make decisions is challenging, particularly when they process complex technical information. Their intricate internal structure makes it difficult to trace how specific outputs are produced.
- Lack of Transparency: The complexity of LLMs can make it hard to understand how different components interact to generate results, reducing trust in their outputs.
- Need for Interpretability: Ensuring that LLMs' analyses are interpretable is crucial. This involves making the decision-making process transparent and understandable.
- Building Trust: Interpretability is essential for fostering trust in LLMs, especially when their outputs are used for critical decision-making.
Large Language Models (LLMs) are highly sensitive to updates and parameter adjustments, which can lead to unexpected changes in their performance and behavior. This sensitivity underscores the challenges in maintaining consistent output across versions.
-
Sensitivity to Parameter Adjustments: LLMs often exhibit significant variations in outputs and behaviors when their underlying parameters are updated.
-
Illustrative Case:
-
In March 2023, GPT-4 demonstrated exceptional performance in identifying prime numbers.
-
By June 2023, following updates, GPT-4 struggled with the same type of questions.
-
Implications: These inconsistencies highlight the vulnerability of LLMs to modifications, impacting reliability and trust in their performance.
Output inconsistency in LLMs refers to their failure to produce responses that align with user intent or task requirements, even when the prompt is explicit. This issue, which worsens with problem complexity, poses challenges for applications in domains like telecom system optimization.
NOTE : As of today (Jan 25,2025), I think this issue has been improved a lot with the latest models (e.g, chatGPT o, o1 and Gemini Pro 1.5). However I still wouldn't say it is not with any of these issues.
Currently (as of Dec 2024), there are a few open source datasets well described in some reference documents as summarized below.
-
Description: A comprehensive collection of all 3GPP documents from Release 8 to Release 19 (1999-2023), totaling 13.5 GB with 30,137 documents and 535 million words.
-
- Reference : TSpec-LLM: An Open-source Dataset for LLM Understanding of 3GPP Specifications
- Contact : Mohamed Benzaghta
- Preparation:
-
Downloaded zipped 3GPP specification files by release version using a Python utility.
-
Unzipped files and organized them into release folders.
-
Converted .DOC files to .DOCX format using headless LibreOffice software.
-
Used Pandoc to convert .DOCX files to .md (markdown) format.
-
Created a set of questionnaires with varying difficulty levels (easy, medium, complex) to evaluate LLMs using the dataset.
-
Employed an LLM to generate multiple-choice questions and another LLM to verify the difficulty level.
-
Conducted human evaluation for conflicting difficulty assessments.
-
-
Specificity: The dataset is specific to 3GPP standards and may not generalize well to other domains.
-
Complexity: While it retains tables and formulas, effectively utilizing this information for LLM analysis remains a challenge.
-
Unhandled Figures: While it retains text, tables and formulas pretty well, it cannot convert the figures into text. So in most case, Figure parts keeps only the title part and the figure itself are missing.
-
Unhandled Pseudo code: In 3GPP there are some parts described in a kind of pseudo code (especiall for the channel coding parts in 36.211, 36.212, 38.212, 38.212 and I noticed many portions of the pseudo code parts got lost)
- Description: A dataset for 5G cellular network protocol analysis containing 3,547,587 sentences with 134M words from 13,094 cellular network specifications and 13 online websites.
- Reference : SPEC5G: A Dataset for 5G Cellular Network Protocol Analysis
- Preparation:
- Collected 3GPP specifications and scraped data from online 5G tutorials.
- Performed standard NLP preprocessing, including removing extra whitespaces, tabs, Unicode characters, HTML tags, etc.
- Filtered out symbols, Unicode characters, tables, and their content to streamline dataset generation.
- Limitations:
- Information Loss: Removing tables and their content omits potentially valuable information like system parameters and configurations.
- Limited Scope: Covers only a subset of 3GPP documents and not all releases and series.
- Underspecification and Ambiguity: The dataset inherits the inherent ambiguity and underspecification present in the original 3GPP specifications.
- Description: TeleQnA is the first benchmark dataset tailored to assess Large Language Models' (LLMs) proficiency in telecommunications knowledge. It contains 10,000 meticulously crafted questions, categorized into lexicon, standards, and research-based questions.
- Source: https://github.com/netop-team/TeleQnA , https://huggingface.co/datasets/netop/TeleQnA/tree/main
- Reference: TeleQnA: A Benchmark Dataset to Assess Large Language Models Telecommunications Knowledge.
- Contact: Ali Maatouk
- Preparation:
- Curated diverse telecommunications documents (e.g., standards, research).
- Preprocessed data for uniformity (e.g., acronym extraction, format standardization).
- Leveraged GPT-3.5 for question generation and validation.
- Human experts reviewed and refined questions for accuracy.
- Incorporated tools to filter non-self-contained and redundant questions.
- Utilized clustering (via OpenAI Ada v2 embeddings) for semantic refinement.
- Limitations:
- Relies on human judgment, introducing potential subjectivity.
- Challenges in generating uniformly self-contained questions.
- Subjectivity from research authors' interpretations may influence question reliability.
Reference
|
|